Abstract
We trained proximal policy optimization (PPO) agents to play the hidden role game The Resistance. Learning whether or not other actors are behaving in your interest, or only pretending to, is a problem widely unstudied in reinforcement learning. We allow the agents to create and develop their own form of communication which allows them to adversarially influence the actions of other agents. We develop several baseline strategies and metrics to evaluate and quantify our training results. A total of 10 models are constructed and used for completing different tasks during the game by two competing teams. We found that the PPO agents can play competitively against our baseline strategies, without training on these baselines. This means the agents not only learn to play against their non-stationary counterparts but learn generic strategies to play against unknown players. Our experimental results show that the agents developed communication in order to identify each other’s roles, resulting in an increase in their win rates. Therefore, we’ve shown that emergent communication is helpful for cooperative and adversarial multi-agent reinforcement learning when there are partially observable states.

Figure 1. The training cycle.
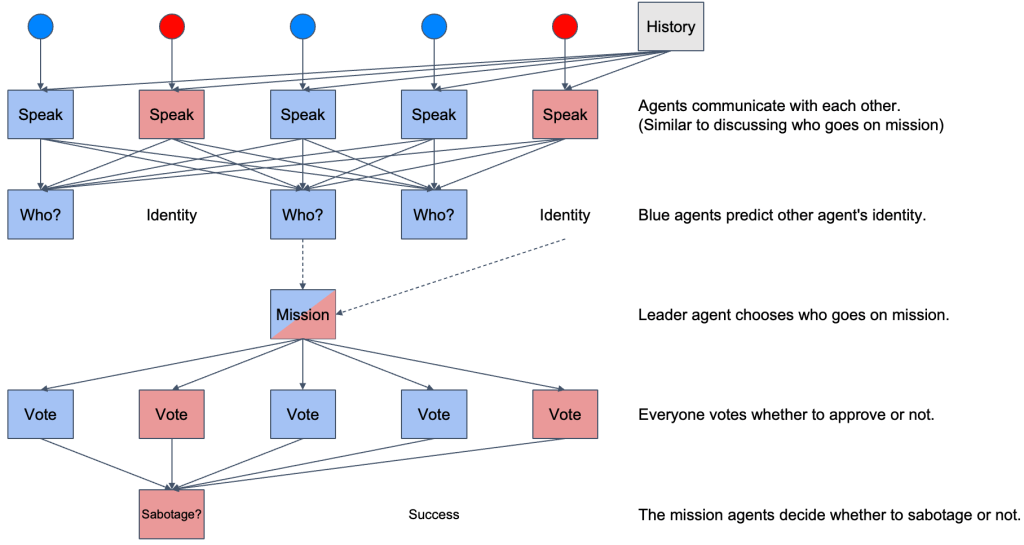
Figure 2. Algorithmic flow in one round.