This project is dedicated to investigating the difficult audio-to-video generation with representation learning. Audio-to-video generation is an interesting problem that has abundant application across several industrial fields. Here, we propose a novel training flow consisting of pre-trained models (StyleGAN3, Wav2Vec2, MTCNN networks), newly trained models (variational autoencoders and transformers), and an adversarial learning algorithm. To the best of the author’s knowledge, this is the first implementation of audio-to-video generation using a pre-trained StyleGAN3. The input is a speech audio sequence and an image of a face. Our model will learn to “animate” the face by predicting facial expressions and lip movements. We find that the latent code of our generative model can be encoded 16-fold into a 96-dim vector that retains the information of the talking face. By using this method, audio-to-video generation can be realized without training any generative models, and only latent codes should be predicted from audio. This minimizes our requirement for dataset size and training time. (The reconstructed videos can be found here.)
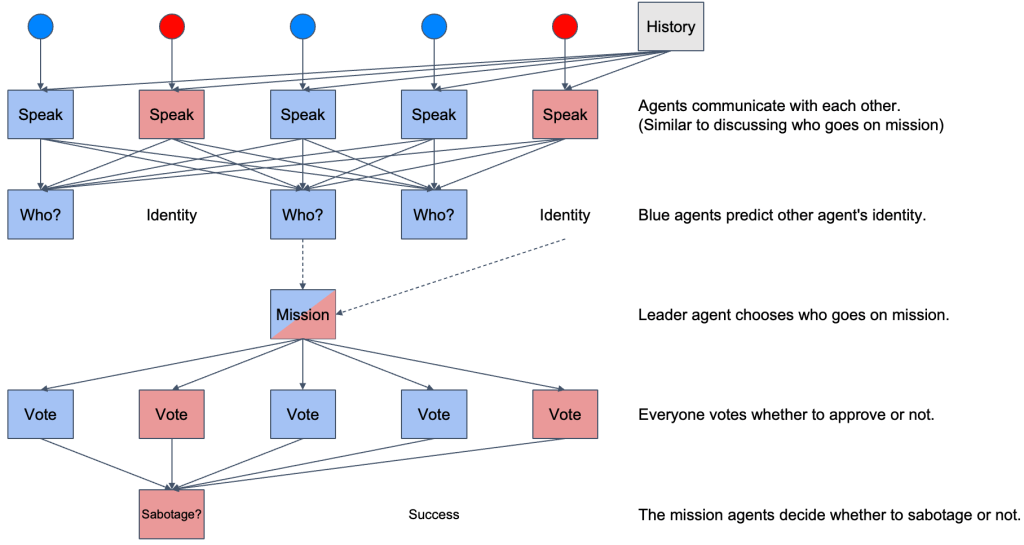
We trained proximal policy optimization (PPO) agents to play the hidden role game The Resistance. Learning whether or not other actors are behaving in your interest, or only pretending to, is a problem widely unstudied in reinforcement learning. We allow the agents to create and develop their own form of communication which allows them to adversarially influence the actions of other agents. We develop several baseline strategies and metrics to evaluate and quantify our training results. A total of 10 models are constructed and used for completing different tasks during the game by two competing teams. We found that the PPO agents can play competitively against our baseline strategies, without training on these baselines. This means the agents not only learn to play against their non-stationary counterparts but learn generic strategies to play against unknown players. Our experimental results show that the agents developed communication in order to identify each other’s roles, resulting in an increase in their win rates. Therefore, we’ve shown that emergent communication is helpful for cooperative and adversarial multi-agent reinforcement learning when there are partially observable states.
I have a great interest in playing puzzle and board games, where elaborate planning or problem solving strategy is a crucial part to succeed or win the game. After starting to learn programming since junior high school, I had written several programs that can compete with human players in a board game, solve a brain-twisting puzzle in less than one second, or play other difficult games by taking advantage of a computer’s computational speed. Here are some game-playing AIs that I had been working on.
This is an end semester project that I have done with my groupmates in college. In this study, we proposed a model to predict a startup company’s future condition using a deep multilayer perceptron (MLP) and decision tree. I mainly played the role for data quantification and literature review of this study. In our study, we built a prediction analysis model for startup companies. Furthermore, we identified what the key factors are and what influences will it have on the results. Our main hypothesis is that money, people and active days are the key factors. We built the prediction model from CrunchBase, which is the largest public database with relevant profiles about companies.
Data Quantification
For the data obtained, there are 4 groups of data that are quantified: country state, employee range, roles and countries. Regarding the states group (which only exists in USA and Canada), we think that different states have different impacts on the survival rate of a startup. A lookup table for scoring of states is defined [1][2][3]. The original data for employee quantities are a range between two numbers (e.g. 101-250). These are transformed into the average of the upper and lower bound. Employees of 10000+ are defined to be 15000. For the roles group, the data “company” is arbitrarily defined as 0.1 and “company, investor” is defined as 0.9. This is because we regard a company as wealthier and influential when it also plays a role of an investor, compared with only being a company. The other roles are transformed to 0.5. The impact of country on startup environment is also studied [4] and scores from 0.329 to 0.947 are given to countries that have above 300 startup companies in record.
Table 1. Company status and scores of 23 countries.
The ANN runs on a Windows 10 OS (i7-8700k CPU) with DDR4 2666MHz 16G RAM and Nvidia GTX 1070 Ti GPU. Keras is used to construct the network, and three networks of multilayer perceptron (MLP) with different number of layers are designed for comparison. There are 4 outputs of the network, indicating the probabilities of the final status which are: (1) Closed, (2) Operating, (3) Acquired and (4) IPO.
Figure 1. MLP Structure of the 3 neural networks.
The three networks have respectively 2, 4 and 6 hidden layers, with each network all starting with a 1024-neuron hidden layer and ending with a 32-neuron hidden layer (Fig. 1). Table 2 shows the training results.
Table 2. Mean square error (MSE) and categorical cross-entropy loss for the 3 networks.
Loss
Activation
Network 1
Network 2
Network 3
MSE
ReLU
0.695
0.694
0.689
MSE
sigmoid
0.690
0.690
0.691
MSE
linear
0.692
0.689
0.692
MSE
tanh
0.688
0.693
0.691
Cross-entropy loss
ReLU
0.695
0.691
0.690
Cross-entropy loss
sigmoid
0.692
0.691
0.691
Cross-entropy loss
linear
0.695
0.692
0.690
Cross-entropy loss
tanh
0.691
0.692
0.691
The results show that almost all results are close to 70% with few difference. In general, ReLU activation has a better result than sigmoid activation, while linear activation may outperform ReLU when the network is deep enough.
The neural network behaves like a black box. It is quite difficult to conclude significant insights just by looking at the trained parameters. However, regarding the importance for business, we used a decision tree to help us understand which factor is the most important and how important they are respectively.
Decision Tree Training
We tried three different depths of decision tree: 4 (Fig. 2), 6 (Fig. 3), and 10. We set the gain ratio to be the criterion, and the confidence to 0.1.
Figure 2. Decision tree of depth = 4.
Figure 3. Decision tree of depth = 6.
The results show that if a company is large enough to exceed 500 people, the close rates are low. In most cases, large companies are acquired by mergers and acquisitions. In addition to the number of employees, funding total amount also has a significant impact on whether a company eventually survives or closes.
Key Findings
Among the factors regarding the ability to survive of starting up companies, the factors such as the number of employees, funding total amount, and the active days have significant influences on the company’s survivability. On the contrary, the factors such as country, region or number of funding rounds do not have significant influences. Whether a company acts as an investor simultaneously will also have influences on whether the company will become an IPO or will be acquired.
Future Work
Our future work is expected to integrate the inspirative insight gained from our case study with the methodology of our own. Three items are listed as in the following:
Construct a heterogeneous relationship network for survival rate prediction [5].
Define a data path score according to HeteSim algorithm [6][7].
Predict company survival rate using MLP, decision tree and other neural networks.
Xiangxiang Zeng, You Li, Stephen C.H. Leung, Ziyu Lin, Xiangrong Liu, Investment behavior prediction in heterogeneous information network, Neurocomputing, Volume 217, 2016, Pages 125-132
Sun, Y., & Han, J. (2012). Mining Heterogeneous Information Networks: Principles and Methodologies. Synthesis Lectures on Data Mining and Knowledge Discovery, 3(2), 1-159
Shi, C., Kong, X., Huang, Y., Yu, P. S., & Wu, B. (2014). HeteSim: A General Framework for Relevance Measure in Heterogeneous Networks. IEEE Transactions on Knowledge and Data Engineering, 26(10), 2479-2492. [6702458].
It is already well-known that in 2016, the computer program AlphaGo became the first Go AI to beat a world champion Go player in a five-game match. AlphaGo utilizes a combination of reinforcement learning and Monte Carlo tree search algorithm, enabling it to play against itself and for self-training. This no doubt inspired numerous people around the world, including me. After constructing the automated forex trading system, I decided to implement reinforcement learning for the trading model and acquire real-time self-adaptive ability to the forex environment.
Environment Setup
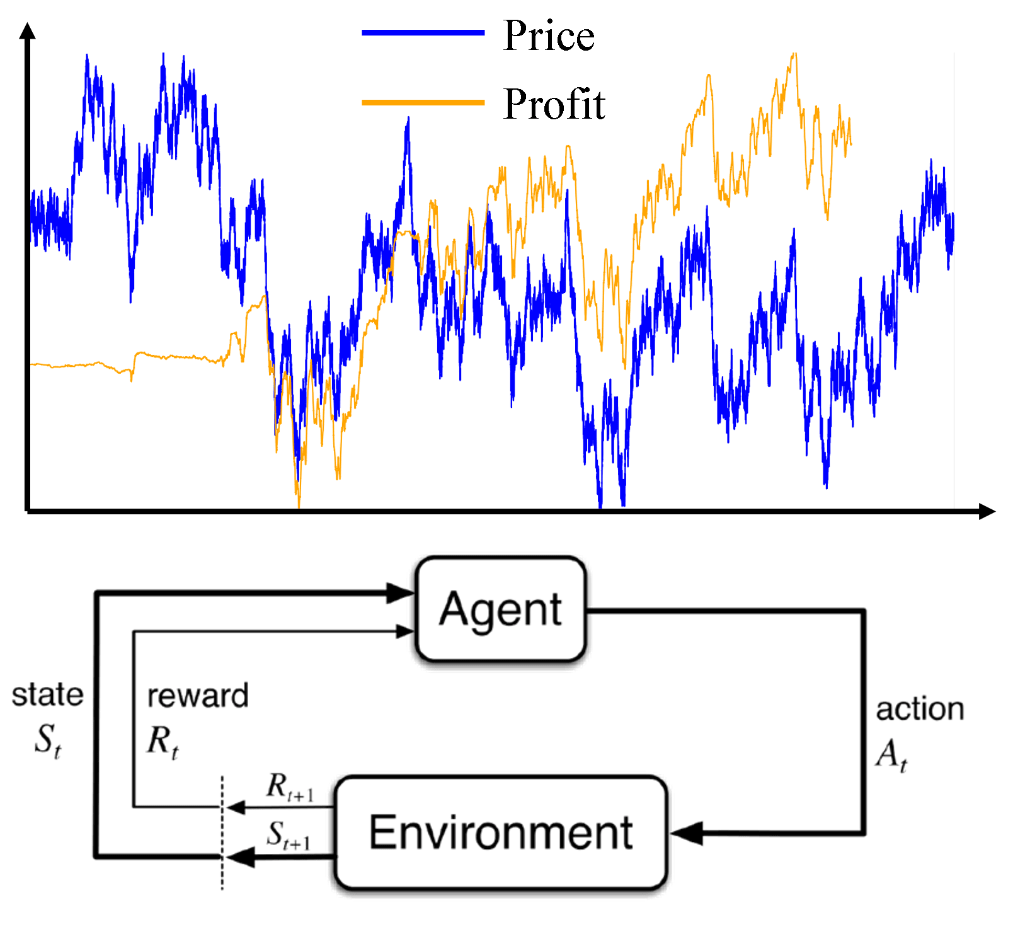
The model runs on a Windows 10 OS (i9-9900K CPU) with DDR4 2666MHz 16G RAM and NVIDIA GeForce RTX 2060 GPU. Tensorflow is used for constructing the artificial neural network (ANN), and a multilayer perceptron (MLP) is used. The code is modified from the Frozen-Lake example of reinforcement learning using Q-Networks. The model training process follows the Q-learning algorithm (off-policy TD control), which is illustrated in Fig. 1.
Figure 1. Algorithm for Q-learning and the agent-environment interaction in a Markov decision process (MDP) [1].
For each step, the agent first observes the current state, feeds the state values into the MLP and outputs an action that is estimated to attain the highest reward, performs that action on the environment, and fetches the true reward for correcting its parameters. The agent follows the epsilon-greedy policy (ε = 0.1) for striking a balance between exploration and exploitation.
State, Action and Reward
For the 1st generation, price values at certain time points and technical indicators are used for constructing the states. The technical indicators used are the exponential moving average (EMA) and Bollinger bands (N=20, k=2), and time frames of 1, 5 and 15min are used with the last 10 time points being recorded. A total number of 36 inputs are connected to the MLP.
There are three action values for the agent: buy, sell and do nothing. The action being taken by the agent is determined by the corresponding three outputs of the MLP, where sigmoid activation functions are used for mapping the outputs to a value range of 0 ~ 1, representing the probability of the agent taking that action.
For the reward function, the difference between the trade price (the price when a buy/sell action is taken) and the averaged future price is considered. If a buy action is taken, then the reward function is calculated by subtracting the averaged future price with the trade price; if a sell action is taken then the reward is calculated the other way around. For “do nothing” actions, the reward is 0. A spread is subtracted from the reward for buy/sell actions to obtain the final reward. This prevents the agent to perform actions that result in insignificant profit, which would likely lead to a loss for real trades (Fig. 2).
Figure 2. Reward calculation method for buy/sell actions.
Noisy Sine Function Test
For preliminary verification of effectiveness for the training model and methods, a noisy sine wave is generated with Brownian motion of offset and distortion in frequency. This means at a certain time point (min), the price is determined by the following equation:
where Pbias is an offset value with Brownian motion, Pamp is the price vibration amplitude, T is the period with fluctuating values, and Pnoise is the noise of the price with randomly generated values. (Note that the “price” mentioned here is defined as the exchange rate between two currencies)
Fig. 3 shows a randomly generated price vs time sequence within a range of 50,000 minutes with an initial values Pbias = 1.0, T = 120 min, Pamp = 0.005, and Pnoise amplitude = 0.001. Generally, the price seems to fluctuate randomly with no obvious highs or lows. However, if it is viewed close-up, waves with clear highs and lows can be observed (Fig. 4).
Figure 3. Price vs time of the noisy sine wave from 0 to 50,000 min.
Figure 4. Price vs time of the noisy sine wave from 20000 to 20600 min.
The whole time period is 1,000,000 min (approximately 700 days, or 2 years). Initially, a random time period is set for the environment. Every time the agent takes an action, there is a certain chance (= 1%) that the time will jump to another random point within the whole period. Otherwise, the time will move on to a random point which is around 1 ~ 2 day(s) in the future. This setting is expected to correspond to real conditions, where a profitable strategy can have stable earnings and can also adapt quickly to rapid changing environments.
Fig. 5 plots the cumulative profit for trading using the noisy sine wave signal for 50,000 steps. Although it took approximately 25,000 steps to make the model get “on track”, I recognize this result as an important start for implementing real data.
Figure 5. Cumulative profit from trading using a noisy sine wave signal.
Fundamental Analysis for Economic Events
Fundamental analysis is a tricky part in forex trading, since economic events not only correlate with each other, but also might have opposite effects on the price at different conditions. In this project, I extracted the events that are considered significant, and contain previous, forecast and actual values for analysis. Data from 14 countries of the past 10 years are downloaded and columns with incomplete values are abandoned, making a complete table of economic events.
Because different events have different impacts on forex, the price change after the occurrence of an event is monitored, and a correlation between each event and the seven major pairs (commodity pairs). Table 1 displays a portion of the correlation table for different economic events. The values are positive, which indicates the significance of an event on the currency pair. Here, a pair is denoted by the currency other than the USD (e.g. USD/JPY is denoted as JPY).
Table 1. Correlation table between 14 events and 5 currency pairs. Here, a pair is abbreviated as the currency other than the USD.
Country
Economic Event (Index)
AUD
CAD
EUR
GBP
JPY
AUD
Commodity Prices
0.00313
0.00268
0.00266
0.00339
0.00278
AUD
MI Inflation Expectations
0.00338
0.00168
0.00217
0.00200
0.00266
AUD
RBA Interest Rate Decision
0.00428
0.00262
0.00258
0.00298
0.00225
EUR
Manufacturing PMI
0.00331
0.00284
0.00263
0.00298
0.00278
EUR
Italian CPI
0.00315
0.00319
0.00295
0.00316
0.00255
EUR
Services PMI
0.00341
0.00290
0.00293
0.00295
0.00284
EUR
CPI
0.00304
0.00294
0.00262
0.00317
0.00241
EUR
German Unemployment Rate
0.00315
0.00315
0.00273
0.00313
0.00246
EUR
ECB President Trichet Speaks
0.00344
0.00248
0.00341
0.00302
0.00268
EUR
German Unemployment Change
0.00313
0.00313
0.00268
0.00307
0.00243
EUR
German Trade Balance
0.00306
0.00255
0.00300
0.00284
0.00268
EUR
German Factory Orders
0.00292
0.00265
0.00312
0.00280
0.00275
EUR
German Retail Sales
0.00304
0.00304
0.00353
0.00310
0.00275
EUR
French Trade Balance
0.00312
0.00312
0.00296
0.00301
0.00299
A total of 983 events are analyzed. However, due to the fact that a large portion of events have little influence on the price, only 125 events that have a relatively significant impact are selected as the inputs of the MLP.
Real Data Implementation Results
Per-minute exchange rate data of the seven currency pair is downloaded from histdata.com. A period from 2010 to 2019 is extracted, and blank values are filled by interpolation. This gives us a total of approximately 23 million records of price data (note that weekends have no forex data records), and is deemed sufficient for model training. The data is integrated into a table, and technical indices are calculated using ta, a technical analysis library for Python built on Pandas and Numpy.
Figure 6. EUR/USD exchange rate from 2010 to 2019.
Summing the inputs from technical analysis, fundamental analysis, and pure price data, a total of 1049 inputs are fed into the MLP. Within the hidden layers, ReLU activation is used, and a sigmoid activation function is used for the output layer. The output has a shape of 7×3, which represents the probability of the seven currency pairs and the three actions (buy, sell, do nothing).
Fig. 7 shows the accumulative profit from 2,000,000 steps in a single episode and its win rate (percentage of profitable trades within a moving average). An increasing spread value from 0.00001 to 0.00004 is applied, which the spread value starts from 0.00001 and increases by 0.00001 every 50,000 step. It can be seen that overall, the accumulative profit rises steadily. However, the win rate usually falls below the 50% line. How could a profitable trading strategy be possible? This is due to the fact that the average profit of a winning trade (=0.003736) is larger than the average loss of a losing trade (=0.003581). Thus, the overall result is a profitable trading strategy.
Figure 7. Accumulative profit and win rate from the training procedure of 2,000,000 steps.
Conclusion
In conclusion, a trading model for profitable forex trading is developed using reinforcement learning. The model can automatically adapt to dynamic environments to maximize its profits. Although for real conditions that have a larger spread, the model hasn’t achieved a stable and profitable result, the potential for optimizing is promising. In the future, I am planning to integrate this trading model with the automated forex trading system that I have made, and become a competitive player in this fascinating game of forex.