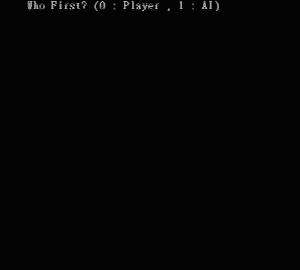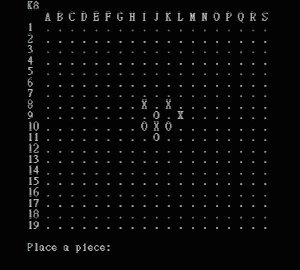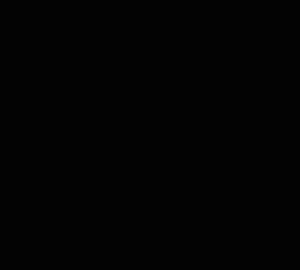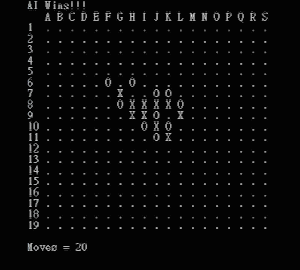
Othello (a variant of the traditional game Reversi) is a two-player strategy board game played on an 8×8 square field, where each player takes turns placing black or white pieces and capturing the other player’s pieces.

Figure 1. Othello board game.
The Othello AI program is the second board game AI that I have written in junior high school (the first is the Tic-Tac-Toe AI). Just like the programming strategy for the tic-tac-toe AI, I used the logic thinking experiences that I had learned while playing this game, and hard-coded some summarized strategies into this program.
Compared with the tic-tac-toe AI, which has a game-tree complexity of 9! = 362880, Othello is much more complex, yielding a stunning complexity of approximately 1058. This makes the game still mathematically unsolved up to this very day. Therefore, instead of calculating the definite winning strategy, this Othello AI rather tries to find relative advantageous points (e.g. the corners), and moves that will temporarily maximize the number of pieces which it occupies by the coded algorithm, making it a beginner ~ intermediate level AI.
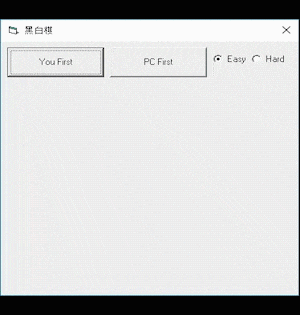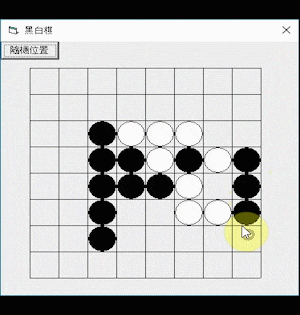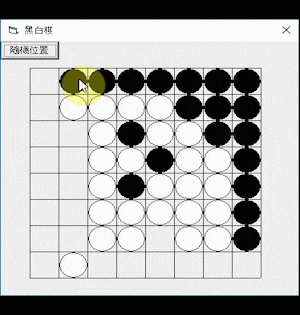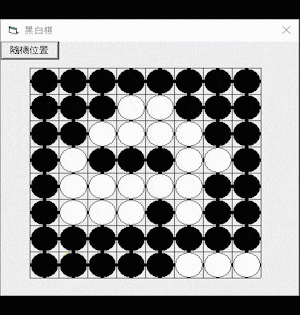
Here is a demonstration of using the Othello AI program:
[Source code for the Othello AI program (Visual Basic 6.0 form file)]