It is already well-known that in 2016, the computer program AlphaGo became the first Go AI to beat a world champion Go player in a five-game match. AlphaGo utilizes a combination of reinforcement learning and Monte Carlo tree search algorithm, enabling it to play against itself and for self-training. This no doubt inspired numerous people around the world, including me. After constructing the automated forex trading system, I decided to implement reinforcement learning for the trading model and acquire real-time self-adaptive ability to the forex environment.
Environment Setup
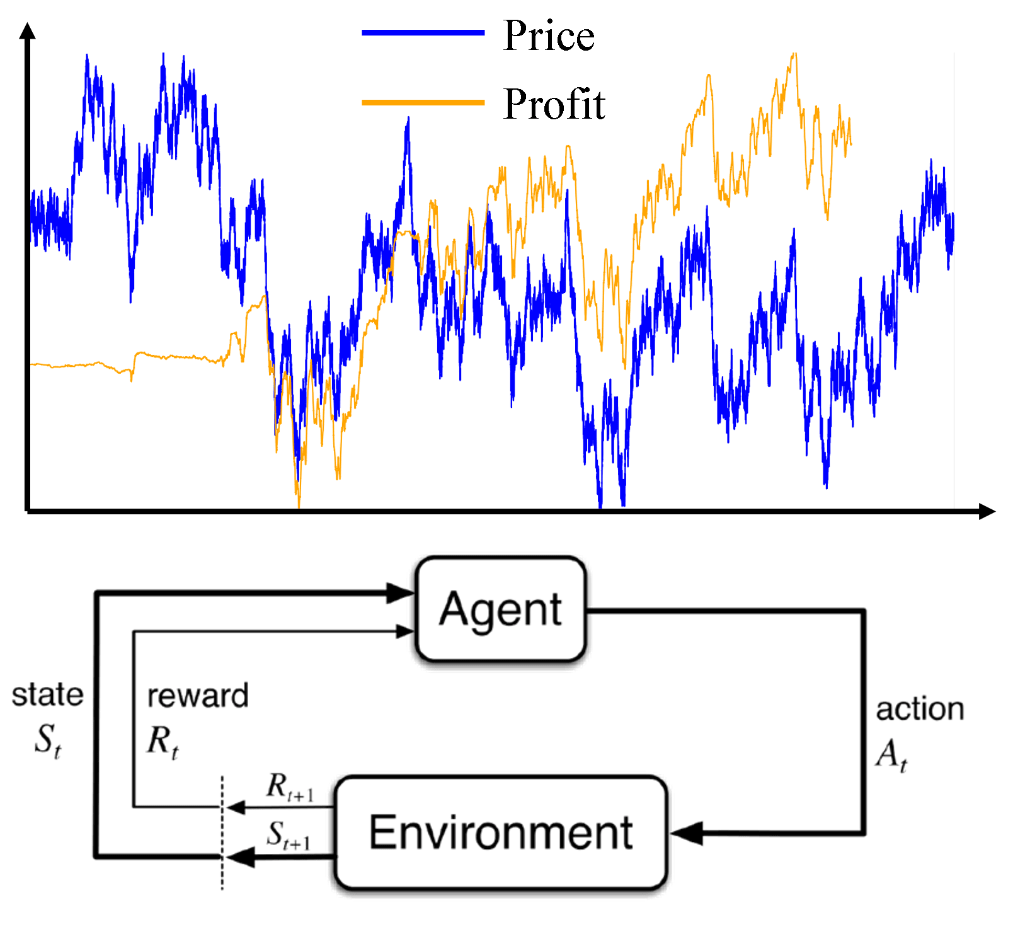
The model runs on a Windows 10 OS (i9-9900K CPU) with DDR4 2666MHz 16G RAM and NVIDIA GeForce RTX 2060 GPU. Tensorflow is used for constructing the artificial neural network (ANN), and a multilayer perceptron (MLP) is used. The code is modified from the Frozen-Lake example of reinforcement learning using Q-Networks. The model training process follows the Q-learning algorithm (off-policy TD control), which is illustrated in Fig. 1.

Figure 1. Algorithm for Q-learning and the agent-environment interaction in a Markov decision process (MDP) [1].
For each step, the agent first observes the current state, feeds the state values into the MLP and outputs an action that is estimated to attain the highest reward, performs that action on the environment, and fetches the true reward for correcting its parameters. The agent follows the epsilon-greedy policy (ε = 0.1) for striking a balance between exploration and exploitation.
State, Action and Reward
For the 1st generation, price values at certain time points and technical indicators are used for constructing the states. The technical indicators used are the exponential moving average (EMA) and Bollinger bands (N=20, k=2), and time frames of 1, 5 and 15min are used with the last 10 time points being recorded. A total number of 36 inputs are connected to the MLP.
There are three action values for the agent: buy, sell and do nothing. The action being taken by the agent is determined by the corresponding three outputs of the MLP, where sigmoid activation functions are used for mapping the outputs to a value range of 0 ~ 1, representing the probability of the agent taking that action.
For the reward function, the difference between the trade price (the price when a buy/sell action is taken) and the averaged future price is considered. If a buy action is taken, then the reward function is calculated by subtracting the averaged future price with the trade price; if a sell action is taken then the reward is calculated the other way around. For “do nothing” actions, the reward is 0. A spread is subtracted from the reward for buy/sell actions to obtain the final reward. This prevents the agent to perform actions that result in insignificant profit, which would likely lead to a loss for real trades (Fig. 2).

Figure 2. Reward calculation method for buy/sell actions.
Noisy Sine Function Test
For preliminary verification of effectiveness for the training model and methods, a noisy sine wave is generated with Brownian motion of offset and distortion in frequency. This means at a certain time point (min), the price is determined by the following equation:
$$P(t)=P_{bias} + P_{amp} sin{2\pi \over T}t+P_{noise}$$
where Pbias is an offset value with Brownian motion, Pamp is the price vibration amplitude, T is the period with fluctuating values, and Pnoise is the noise of the price with randomly generated values. (Note that the “price” mentioned here is defined as the exchange rate between two currencies)
Fig. 3 shows a randomly generated price vs time sequence within a range of 50,000 minutes with an initial values Pbias = 1.0, T = 120 min, Pamp = 0.005, and Pnoise amplitude = 0.001. Generally, the price seems to fluctuate randomly with no obvious highs or lows. However, if it is viewed close-up, waves with clear highs and lows can be observed (Fig. 4).

Figure 3. Price vs time of the noisy sine wave from 0 to 50,000 min.

Figure 4. Price vs time of the noisy sine wave from 20000 to 20600 min.
The whole time period is 1,000,000 min (approximately 700 days, or 2 years). Initially, a random time period is set for the environment. Every time the agent takes an action, there is a certain chance (= 1%) that the time will jump to another random point within the whole period. Otherwise, the time will move on to a random point which is around 1 ~ 2 day(s) in the future. This setting is expected to correspond to real conditions, where a profitable strategy can have stable earnings and can also adapt quickly to rapid changing environments.
Fig. 5 plots the cumulative profit for trading using the noisy sine wave signal for 50,000 steps. Although it took approximately 25,000 steps to make the model get “on track”, I recognize this result as an important start for implementing real data.

Figure 5. Cumulative profit from trading using a noisy sine wave signal.
Fundamental Analysis for Economic Events
Fundamental analysis is a tricky part in forex trading, since economic events not only correlate with each other, but also might have opposite effects on the price at different conditions. In this project, I extracted the events that are considered significant, and contain previous, forecast and actual values for analysis. Data from 14 countries of the past 10 years are downloaded and columns with incomplete values are abandoned, making a complete table of economic events.
Because different events have different impacts on forex, the price change after the occurrence of an event is monitored, and a correlation between each event and the seven major pairs (commodity pairs). Table 1 displays a portion of the correlation table for different economic events. The values are positive, which indicates the significance of an event on the currency pair. Here, a pair is denoted by the currency other than the USD (e.g. USD/JPY is denoted as JPY).
Table 1. Correlation table between 14 events and 5 currency pairs. Here, a pair is abbreviated as the currency other than the USD.
| Country | Economic Event (Index) | AUD | CAD | EUR | GBP | JPY |
| AUD | Commodity Prices | 0.00313 | 0.00268 | 0.00266 | 0.00339 | 0.00278 |
| AUD | MI Inflation Expectations | 0.00338 | 0.00168 | 0.00217 | 0.00200 | 0.00266 |
| AUD | RBA Interest Rate Decision | 0.00428 | 0.00262 | 0.00258 | 0.00298 | 0.00225 |
| EUR | Manufacturing PMI | 0.00331 | 0.00284 | 0.00263 | 0.00298 | 0.00278 |
| EUR | Italian CPI | 0.00315 | 0.00319 | 0.00295 | 0.00316 | 0.00255 |
| EUR | Services PMI | 0.00341 | 0.00290 | 0.00293 | 0.00295 | 0.00284 |
| EUR | CPI | 0.00304 | 0.00294 | 0.00262 | 0.00317 | 0.00241 |
| EUR | German Unemployment Rate | 0.00315 | 0.00315 | 0.00273 | 0.00313 | 0.00246 |
| EUR | ECB President Trichet Speaks | 0.00344 | 0.00248 | 0.00341 | 0.00302 | 0.00268 |
| EUR | German Unemployment Change | 0.00313 | 0.00313 | 0.00268 | 0.00307 | 0.00243 |
| EUR | German Trade Balance | 0.00306 | 0.00255 | 0.00300 | 0.00284 | 0.00268 |
| EUR | German Factory Orders | 0.00292 | 0.00265 | 0.00312 | 0.00280 | 0.00275 |
| EUR | German Retail Sales | 0.00304 | 0.00304 | 0.00353 | 0.00310 | 0.00275 |
| EUR | French Trade Balance | 0.00312 | 0.00312 | 0.00296 | 0.00301 | 0.00299 |
A total of 983 events are analyzed. However, due to the fact that a large portion of events have little influence on the price, only 125 events that have a relatively significant impact are selected as the inputs of the MLP.
Real Data Implementation Results
Per-minute exchange rate data of the seven currency pair is downloaded from histdata.com. A period from 2010 to 2019 is extracted, and blank values are filled by interpolation. This gives us a total of approximately 23 million records of price data (note that weekends have no forex data records), and is deemed sufficient for model training. The data is integrated into a table, and technical indices are calculated using ta, a technical analysis library for Python built on Pandas and Numpy.

Figure 6. EUR/USD exchange rate from 2010 to 2019.
Summing the inputs from technical analysis, fundamental analysis, and pure price data, a total of 1049 inputs are fed into the MLP. Within the hidden layers, ReLU activation is used, and a sigmoid activation function is used for the output layer. The output has a shape of 7×3, which represents the probability of the seven currency pairs and the three actions (buy, sell, do nothing).
Fig. 7 shows the accumulative profit from 2,000,000 steps in a single episode and its win rate (percentage of profitable trades within a moving average). An increasing spread value from 0.00001 to 0.00004 is applied, which the spread value starts from 0.00001 and increases by 0.00001 every 50,000 step. It can be seen that overall, the accumulative profit rises steadily. However, the win rate usually falls below the 50% line. How could a profitable trading strategy be possible? This is due to the fact that the average profit of a winning trade (=0.003736) is larger than the average loss of a losing trade (=0.003581). Thus, the overall result is a profitable trading strategy.

Figure 7. Accumulative profit and win rate from the training procedure of 2,000,000 steps.
Conclusion
In conclusion, a trading model for profitable forex trading is developed using reinforcement learning. The model can automatically adapt to dynamic environments to maximize its profits. Although for real conditions that have a larger spread, the model hasn’t achieved a stable and profitable result, the potential for optimizing is promising. In the future, I am planning to integrate this trading model with the automated forex trading system that I have made, and become a competitive player in this fascinating game of forex.
[Source code of RL model training section]
References
[1] R.S. Sutton, A.G. Barto, Reinforcement Learning: An Introduction, MIT Press2018.








